

Que peut-on faire au niveau vidéos, avec l'IA aujourd'hui ?
#11 - Etat de la technique à fin mars 2026

Bonjour !
Dans ce nouveau numéro de Founder Naked, j’ai souhaité faire le point sur ce que l’on est capable de faire aujourd’hui avec l’IA… en vidéo 🎬 !
On parle tout le temps des usages généralistes, des agents IA, et du codage. Mais très rarement de la vidéo, hormis quelques coups de pub pour Sora (RIP) ou Veo. Alors aujourd’hui, je te propose de faire le point sur ce que tu peux vraiment faire à date.
C’est parti !

Si ce n’est pas déjà le cas, tu peux aussi :
Me suivre sur LinkedIn, où je publie des posts complémentaires,
Découvrir les services que je propose, notamment dans le secteur de la finance…
… mais pas encore découvrir Licorn, ma nouvelle boîte.
Au programme
Pourquoi je m’intéresse à la vidéo IA
Qui sont les acteurs en présence
Qu’est-ce que tu peux générer aujourd’hui (dont exemples)
Quels outils tu peux utiliser pour le faire (dont exemples)
Pourquoi je m’intéresse à la vidéo IA
La vidéo IA, c’est encore le Far West.
Je veux dire, l’IA de manière générale, c’est le Far West. Il y a une nouveauté quasi quotidiennement, voire plusieurs fois par jour parfois, et il faut suivre pour rester à la page et connaître les derniers « trucs » que l’on peut faire.
Eh bien pour la vidéo, c’est pire.

La semaine dernière, j’ai testé un outil… qui n’avait même pas de documentation ! Le truc était sorti en grande pompe, avec une vidéo qui a fait le buzz. Tu vas pour tester l’outil — qui reste somme toute assez complexe — et si tu cherches comment faire un truc… et bien il y a tout simplement zéro documentation. Pas le temps d’en produire une.
Tu as « juste » un chat IA qui peut répondre à tes questions et t’aider à démarrer. Mais, le chat IA n’a pas accès à une base de connaissances exhaustive, donc le maître mot c’est “débrouilles-toi”.
En gros cela va tellement vite que les boîtes IA produisent, produisent… mais n’ont pas toujours le temps (ou choisissent de ne pas prendre le temps) pour tout ce qui va autour du produit.
Alors on pourrait discuter du “c’est bien / c’est pas bien”, mais personnellement, ce que je retiens, c’est que :
La vidéo IA évolue super vite, et tout le monde ne peut pas se tenir à jour. C’est donc un immense potentiel pour ceux qui veulent s’y mettre, et l’utiliser pour promouvoir leur activité ou leur produit.
Pour ma part, je l’ai complètement intégrée à ma stratégie marketing. Je veux dire, ce n’est pas juste un outil : c’est un game changer. Cela ouvre de nouvelles possibilités, une nouvelle façon de penser, et cela change fondamentalement ce que l’on peut faire en tant que startup, pour faire sa promotion.
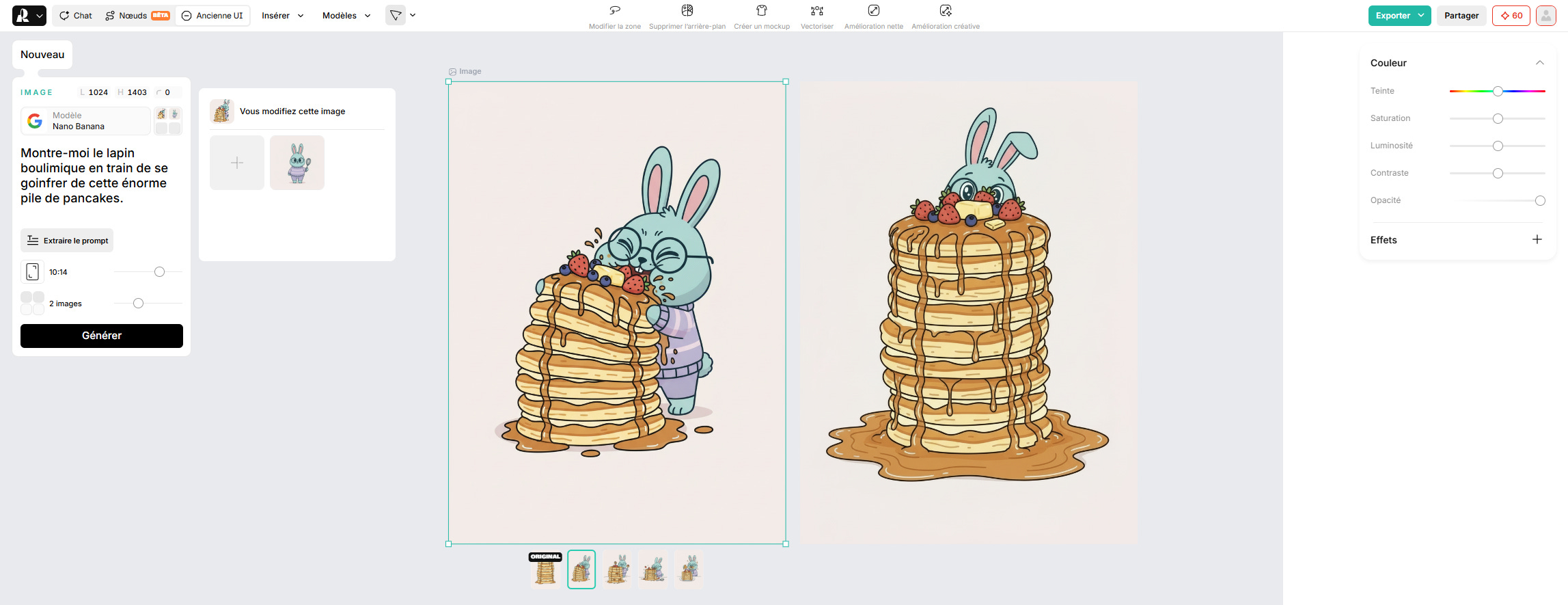
Pour la suite de cette édition, je vais donc en partie me baser sur mes applications concrètes de ces technologies : comment je réalise des vidéos culinaires avec une mascotte, et ma participation au concours Runway’s Big Ad Contest, qui consiste à produire une pub vidéo IA pour un produit qui n’existe pas.
Qui sont les acteurs en présence
En gros tu as des Américains et des Chinois.
Tu retrouves les acteurs américains traditionnels, avec OpenAI et Google qui ont leurs modèles vidéo flagship (Sora et Veo), ainsi que des startups américaines, très connectées à l’univers de la pub et d’Hollywood, qui proposent des outils et modèles spécialisés.
Et côté chinois, tu as pas mal d’acteurs qui proposent des modèles, et éventuellement des outils, pour concevoir des vidéos IA. Leur gros point fort : la compréhension des personnages.
On sent une très forte empreinte en Chine de toute l’industrie du jeu vidéo et de l’animation. Je l’avais déjà remarqué pour la génération de personnages 3D — j’en parlais dans ma newsletter #8 dédiée à ce sujet — ils ont un temps d’avance sur le sujet. Je pense que les acteurs chinois prendront à terme le lead sur l’industrie des personnages.
On peut faire le parallèle avec Tencent et ses prises de participations dans diverses sociétés occidentales de jeux vidéo (Ubisoft par exemple, mais aussi plein de petits studios) : la Chine développe, grâce à sa technique, son économie et ses investissements, une expertise dans le domaine de l’animation des personnages, notamment 3D.
Ainsi, pour en revenir au sujet, on retrouve une expertise différente, et complémentaire, entre les deux côtés du monde :
les Américains sont très bons pour la compréhension globale des scènes et le rendu réaliste des jeux de lumière et du grain,
tandis que les Chinois sont très forts sur la compréhension des personnages, de leurs membres, de ce qu'ils tiennent ou utilisent, etc.
Qu’est-ce que tu peux générer aujourd’hui
En termes de style (réaliste, cartoon, 3D…), tu peux tout faire. Il n’y a plus de limite, on peut générer des vidéos dans n’importe quel style, et ce style reste cohérent de scène en scène.
Je te mets ci-dessous un aperçu des styles dans Flick, un nouveau logiciel américain qui a tout juste 3 mois (celui qui a zéro doc). Le scroll est quasi infini, donc je te montre juste les premières dizaines de styles, pour te donner un aperçu de la variété de styles que l’on peut utiliser 👇
Et ces styles ne sont que des exemples de choses existantes. On peut tout à fait créer son propre style et ensuite le faire suivre dans toutes ses scènes.
Principe 1 : on part toujours d’une photo
Alors on peut partir d’un prompt sur les gros modèles types Veo ou Sora, et d’autres. Mais cela consomme énormément de ressources pour un résultat qui est entièrement soumis à l’interprétation du modèle. Donc normalement, on évite.
Ce que l’on fait, c’est que l’on part d’une photo de la scène que l’on veut animer — en général la « first frame » — que l’on passe à un modèle vidéo avec un prompt vidéo. Certains modèles acceptent également une « last frame » ; on produit alors l’image de début et l’image de fin, et on demande au modèle vidéo d’animer l’entre-deux.
🎬 Exemple concret
Prompt photo pour Nano Banana Pro (Google, américain) :
Années 1960, New York, style vestimentaire et décor d’époque. Format cinéma 2.39:1, profondeur de champ courte, qualité cinématographique 35mm. Plan large d’un couple sortant d’un cinéma de quartier sur l’Upper West Side de New York en automne, soirée. Marquise lumineuse avec des lettres rétro derrière eux. Homme, 25 ans, cheveux bruns mi-courts légèrement décoiffés, veste en tweed brun-beige avec coudières, chemise blanche col ouvert, pantalon flanelle gris, chaussures cuir marron. Femme, 25 ans, cheveux châtains longs détachés, manteau camel ceinturé à la taille col relevé, robe bleu marine en dessous, bottes cuir marron, écharpe laine crème. Ils rient ensemble, épaules qui se touchent, complicité évidente. Feuilles mortes sur le trottoir, lumière chaude dorée des néons, tons ambre et brun. Grain de pellicule léger.
Rendu de la photo :

Prompt vidéo pour Gen 4.5 Video (américain) puis pour Kling 3.0 Pro (chinois) :
La caméra recule doucement en travelling arrière. Le couple avance vers la caméra en riant. Elle lui donne un léger coup d’épaule joueur. Les feuilles mortes tourbillonnent à leurs pieds au passage d’un taxi. Lumière chaude, mouvement lent et fluide.
Rendu de la vidéo sur Runway Gen 4.5 Video :
Rendu de la vidéo sur Kling 3.0 Pro :
Comme on peut le voir, avec la même image en entrée et le même prompt, le rendu n’est absolument pas le même en fonction du modèle vidéo. Et encore, ici on est sur deux très bons modèles vidéos ; il en existe une multitude de pas terribles, où ne serait-ce que le rendu (lumière, grain) n’est absolument pas réaliste.
Principe 2 : itérer tu vas, donc choisis des modèles efficients
Je n’ai pas donné d’exemple avec Veo ou Sora car je ne les utilise pas. Ce sont des modèles flagship, mais ils sont trop chers et la différence de qualité ne vaut pas l’investissement, en tout cas pour de la génération de scènes et de l’itération.
Qu’on s’entende bien : je les ai bien sûr testés.
Mais c’est le genre de modèles qui passent bien pour montrer qu’on peut générer des vidéo IA whaouuu, mais sans prompt bien précis. Donc pour faire un truc à peu près :
Je veux générer un mec qui marche dans un bureau (peu importe lequel), et tout le monde se lève et est content, et d’un coup le sol se fracture.
Pour ça par exemple c’est cool, ça produit un rendu très propre, les effets spéciaux sont tops et c’est tout de suite impressionnant. Ainsi, si on veut faire une vidéo Linkedin pour montrer ses talents, ça marche bien, car le prompt n’a pas à coller à une histoire super précise ; il faut juste que ça fasse whaou.
À l'inverse, si tu fais une pub, ou que tu dois suivre un scénario super précis (une recette de cuisine par exemple), là c’est la looze : tu dois itérer, et ces modèles vont littéralement te coûter 4 à 6 fois plus cher. Pour un rendu et une compréhension de la physique qui ne sont pas forcément mieux, selon les usages.
Donc pour ma part, j’utilise quasi toujours Nano Banana (2 ou Pro, selon les cas) pour générer les images, et pour les vidéos, des modèles spécialisés (Runway, Kling, Wan…).
Principe 3 : bon courage pour la physique
Et c’est là qu’on n’y est pas encore.
Un mec qui marche dans un bureau : facile.
Un mec qui attrape un stylo et écrit sur un post-it : aïe aïe aïe…
🎬 Exemples concrets
Sans y passer trop de temps, je te montre ce que donne une physique ratée dans un exemple au style réaliste : une femme essaie d’attacher une bande de photo et un bout de papier ensemble, à l’aide d’un trombone 👇
On voit que la superposition des deux objets ne marche pas, et que la compréhension de comment fonctionne un trombone est super compliquée en fait.
Et je te mets aussi un exemple de physique culinaire : découper de la pâte à l'emporte-pièce. On voit ici aussi que la compréhension du phénomène — même avec un prompt détaillé — n’est pas encore au niveau 👇
Quels outils tu peux utiliser pour le faire
Concernant les outils, les choses évoluent super vite aussi. On vient d’un mode dans lequel on passe juste en entrée les paramètres d’un modèle. Exemple sur Recraft ci-dessous : je passe à Nano Banana l’image que je souhaite éditer, une image de référence, et un prompt.
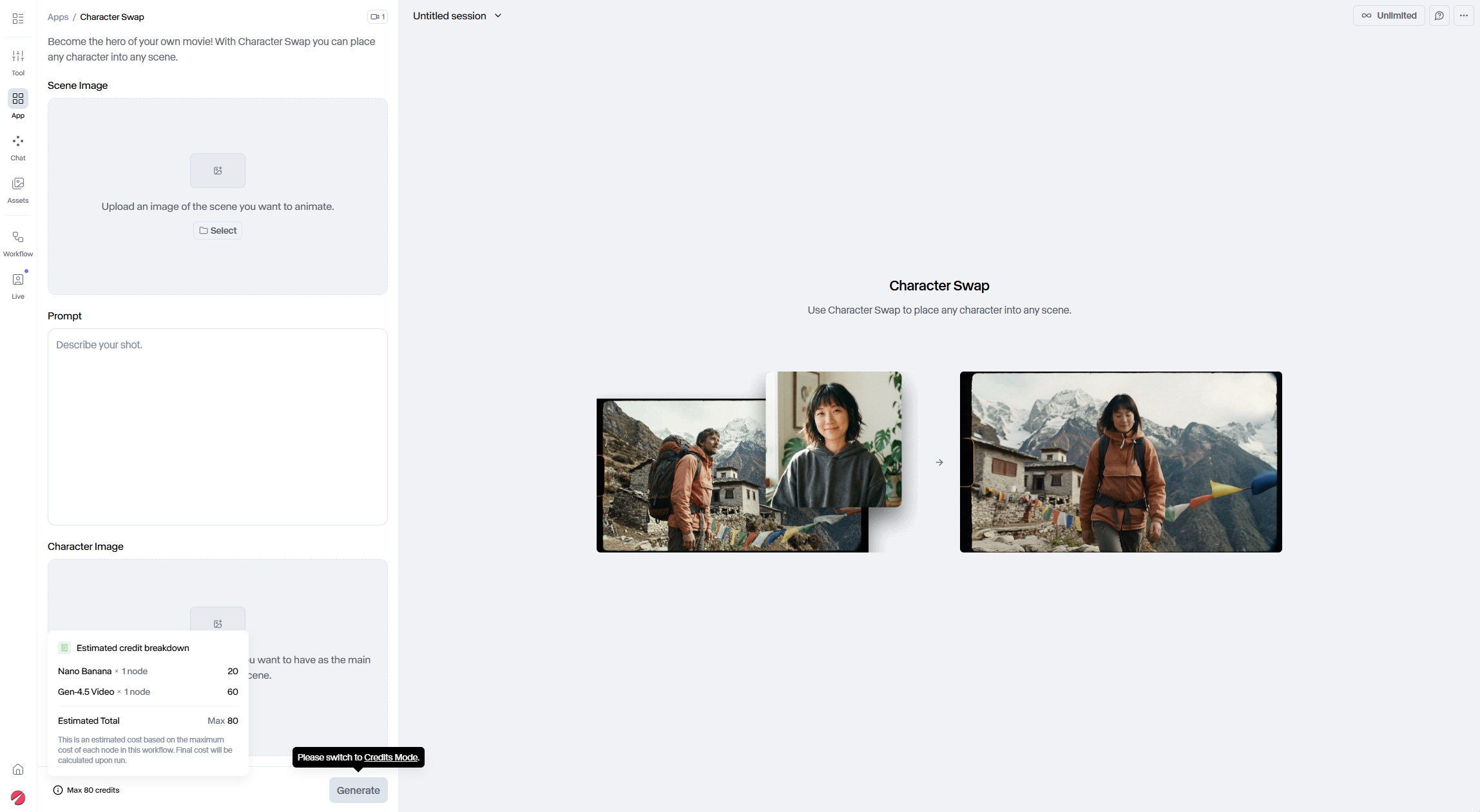
On a ensuite évolué vers des applications qui combinent plusieurs modèles. Par exemple ici dans Runway : on nous propose une application pour changer un personnage sur une vidéo, qui utilise à la fois un modèle image (Nano Banana) et un modèle vidéo (Gen 4.5). Ces applications spécialisées font déjà gagner du temps.
Pour arriver enfin (pour le moment) à un système de workflow : une interface visuelle sur laquelle on connecte des nœuds images et vidéos, pour assembler des scènes et in fine produire une vidéo complète.
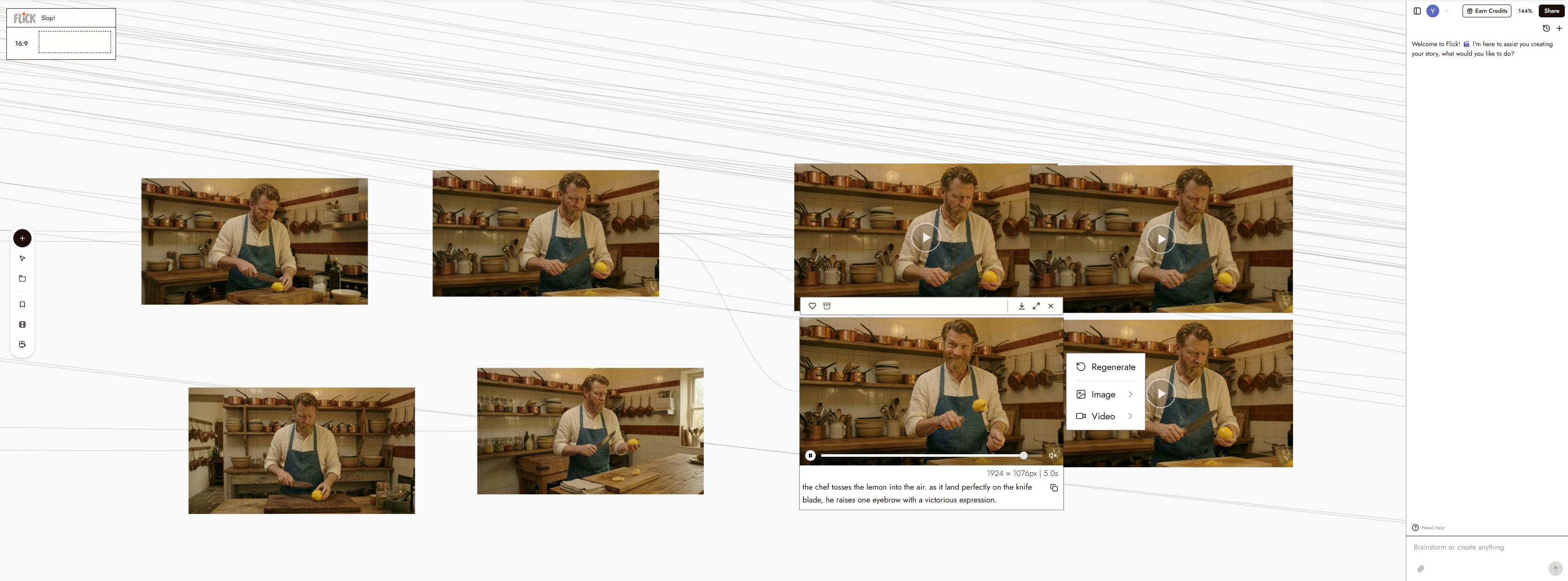
Le mot de la fin
Je dois m’arrêter là, j'atteins la longueur limite imposée par Substack, qui elle-même découle de la limite imposée par Gmail pour l’affichage des emails…
Je terminerai par dire que, niveau outil vidéo, je travaille pour ma part sur Runway, que je trouve à l’heure actuelle le plus complet, même s’il y a des choses à améliorer — mais tout évolue tellement vite !
En tout cas, si tu crées un produit, que tu veux en faire la promotion, ou que tu es juste curieux·se, je t’invite à tester la génération de vidéo par IA.
Et pour ma part, je te détaillerai comment j’ai réalisé mes premières vidéos IA complètes, dans de prochaines éditions de Founder Naked, dès qu’elles seront sorties !
Bonne semaine !
Yoann